こんにちは。グラフィックファシリテーター®やまざきゆにこです。
【NRIプレゼンツ☆知っておきたいデータサイエンス用語】
野村総研 未来創発センター「データサイエンスラボ」さまの新しい取り組み NRI「データサイエンス用語」の解説動画(絵巻物)第15弾がYouTubeアップされました。今回は「モデル評価指標」です。
↓動画はこちら
↓用語解説はこちら
https://www.nri.com/jp/knowledge/glossary/lst/ma/model_evaluation_index
いつもの通りデータサイエンス初心者のわたしが「モデル評価指標って、ざっくりこんな感じ」をこちらで紹介します。
●イントロ
動画のイントロはパパが社長に『モデルの精度が高いって、どうして言えるんだ?』って聞かれてアタフタしているシーンから。

データサイエンティストさんたちは評価指標の結果を見ながらチューニングして予測精度の高いモデルを決めてくれているのですが、中には、機械任せで、評価指標がどんな計算をしているか知らずに使っている人もいたり、評価指標の存在すら知らない人もいるとかいないとか…。
ド素人なわたしは「機械学習を使って予測した」と言われたら「機械学習=いちばん予測精度が高い」と思いこんで信頼しちゃいますが、社長さんのようなツッコミぐらいはできるようでいたいです。ツッコむからには知っておきたい基本を紹介しているのが今回の動画です。
●モデル評価指標とは
予測モデルがどのくらい良いモデルか、どのくらい優れた予測ができているか判断するために、定量的に示す「評価指標」を決めて判断します。評価指標って、とにかくすごい数あるそうです。
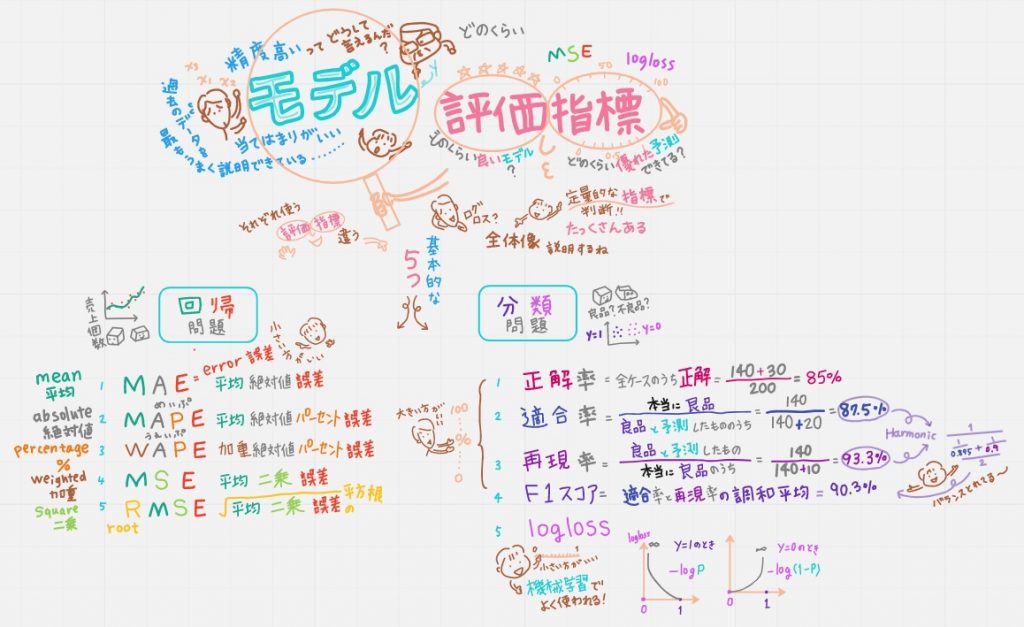
●モデル評価指標 全体像
回帰問題と分類問題で使う評価指標は違うので、それぞれ基本的な5つを動画では紹介します。
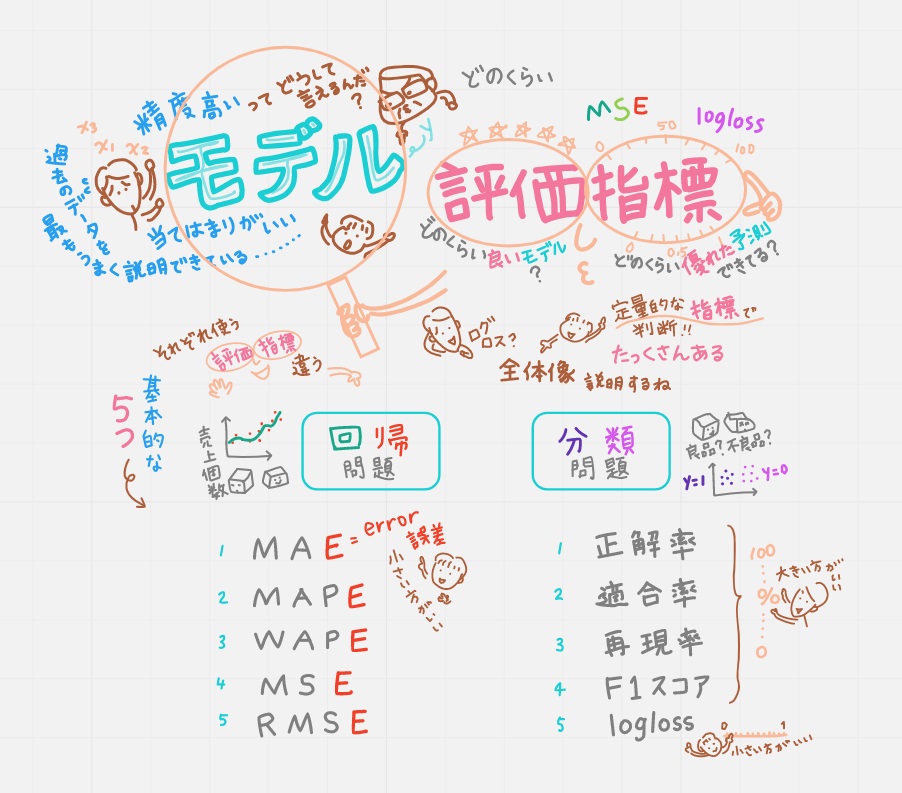
ちなみに上の絵の左上。「精度が高いモデル」とは「当てはまりがいいモデル」とも「過去のデータを最もうまく説明できている」とも言うそうです。「当てはまりがいい」なんて初めて聞いた!2つのモデルを同じ評価指標で比較したとき、「あてはまりがよいモデル」のほうを選んだりするわけですね。
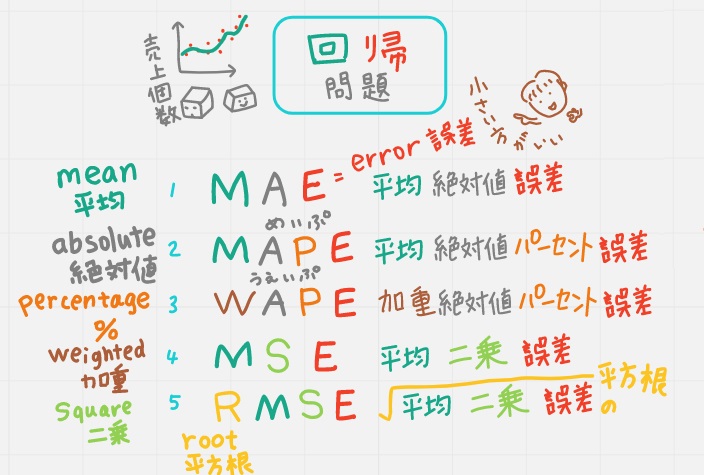
●回帰問題のモデル評価指標5つ
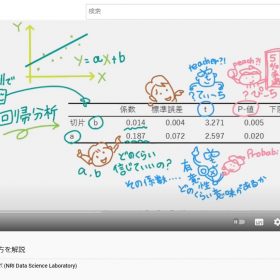
頭文字の意味が分かるとド素人の私にも理解しやすかったので、こんな動画からスタート。すべてE=誤差なるので、数字が小さければ小さいほど「いいモデル」といえます。機械学習でよく使われているのは4,MSEです。
回帰問題の例:(下の絵の右上の表)たとえば「売上個数」の「予測」と「実績」が、こんな表のような結果だったとして、それぞれを考えると分かりやすいデス。
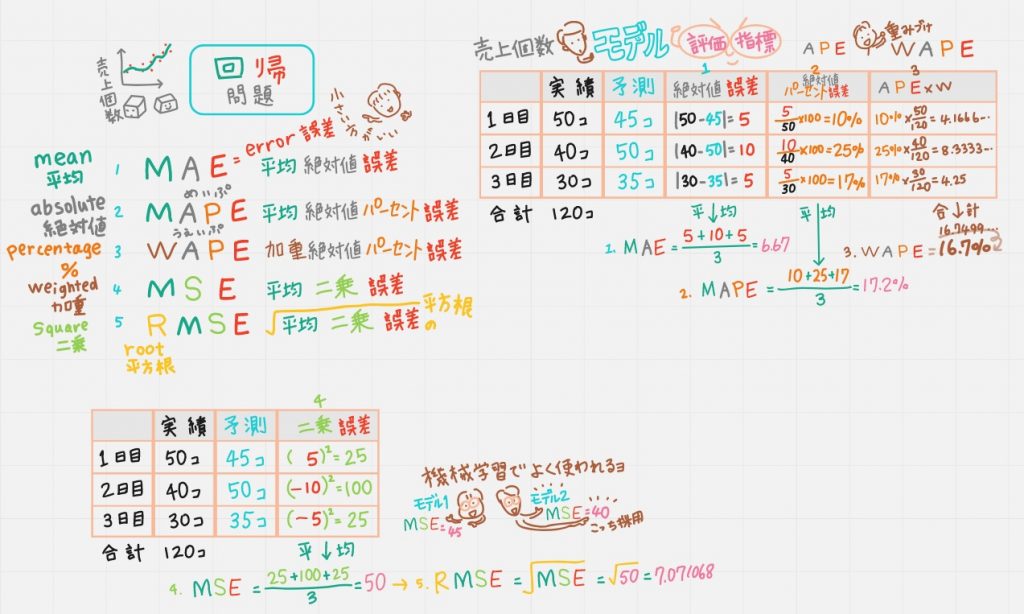
①MAE(平均絶対値誤差)
それぞれの 「実績ー予測」の「絶対値」の「誤差」の平均をとったもの。
②MAPE(平均絶対値パーセント誤差)
それぞれの「絶対値パーセント誤差」の平均をとったもの。
③WAPE(加重絶対値パーセント誤差)
WAPEのWは重みづけ。APEは1つ前のMAPEのAPEと考えると分かりやすいのではないかと思って、こんな動画にしました。1つ目は50/120という重みを掛け、2つ目は40/120という重みを掛け、3つ目は30/120という重みを掛け、3つを足せば16.7%になります。
④MSE(平均二乗(squared)誤差)
MSEは機械学習でよく使われてて、デフォルトになってることも多いそう。
それぞれ「誤差を二乗」して平均をとったもの。誤差にはマイナスのものもあるので「二乗」しています。
⑤RMSE(平均二乗誤差の平方根(root))
「R=ルート平方根」の意味なので上の「MSE」にルートをかけたもです。
●分類問題のモデル評価指標5つ
分類問題の例:(下の絵の右上の表)「200個の箱」が「良品」か「不良品」かを予測する問題で考えると分かりやすいです。表のような結果だったとします。
1~4の指標は「数字が大きいほどいいモデル」となります。
5の指標は「0に近ければ近いほどいいモデル」となります。

①正解率(全ケースのうち正解のもの)
(140+30)÷200=85%
ド素人なわたしは「正解」も「真」も同じ意味だと思いきや、全く別物とのこと。正解とは「真と予測して真だったもの」も正解だし「偽と予測して偽だったもの」も正解なのです。だから140+30になってます。
②適合率(真と予測したもののうち本当に真のもの)表を縦に見ます。
140÷(140+20)=87.5%
③再現率(本当は真のもののうち真と予測したもの)表を横に見ます。
140÷(140+50)=93.3%
④F1スコア(適合率と再現率の調和平均)87.5%と93.3%の調和平均=90.3%
「調和平均って?」という疑問が出てくるのですが、ここではワクチンで考えると分かりやすいので以下で補足しています。
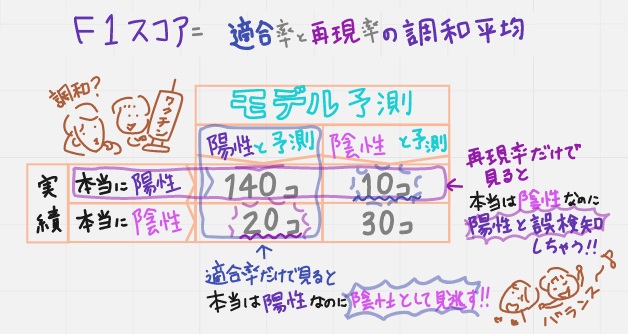
適合率だけ見ると「本当は陽性のものを陰性と見逃す」モデル
再現率だけ見ると「本当は陰性のものを陽性と誤検知する」モデル
となっているので、それら両方のモデルを使って、バランスよいモデルを目指したいときに使える評価指標がF1スコア。
⑤logloss
「ろぐろす」と読みます。機械学習でよく使われる評価指標。
①~④までは「良品か不良品か」「1か0か」で予測してきましたが、機械学習だと「90%の確率で良品(つまり10%の確率で不良品)」と予測できますよね。
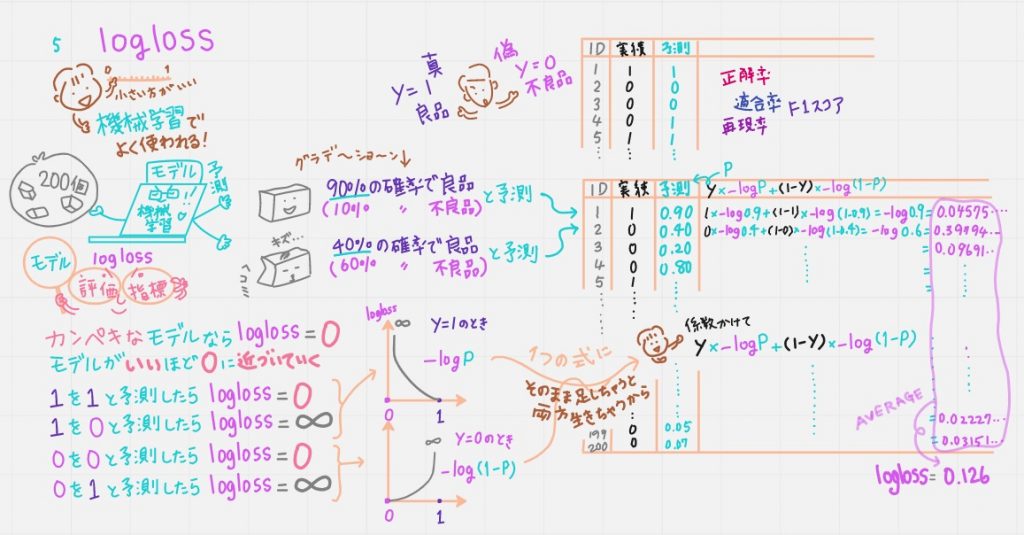
完璧なモデルなら logloss=0とする。
いいモデルほど loglossが0に近づいていく。
とすると、つまり
1を1と予測したらlogloss=0とする
0を0と予測したらlogloss=0とする
1を0と予測したらlogloss=∞とする
0を1と予測したらlogloss=∞とする。
とすると、図にするとこんな曲線を描くよね。
というのが上の絵の真ん中下。それぞれ
-logp
-log(1-p)
と表せる。pは予測確率のことです。
y=1のときは -logp
y=0のときは -log(1-p)
この2つを1つの式にしたいけど
そのまま足しちゃうと両方生きちゃうから係数をかけて
y*-logp+(1-y)*-log(1-p)
これを個々で計算し最後に平均を取ったのがLoglossとなるそうです。
ふぅ~(^^; おつかれさまでした。
●まとめ
●評価指標と機械学習
そもそも機械学習アルゴリズムは、この「評価指標」が最も良くなるように、大量の演算を繰り返しているもの(なので、だからデータサイエンティストさんも無自覚になっちゃうのかな?)
●応用編
これらは基本的な評価指標ですが、応用編として、例えば、特定の重みを付けたモデルを作りたいときに、ユーザ定義の評価指標を定義することができるそう。こういう特定のドメインに合わせたモデルを機械的に生成することもできるそう。標準的な評価指標を使うだけでなく、自分の目的に応じて評価指標をカスタマイズすることも求められるそうです。