こんにちは。グラフィックファシリテーター®やまざきゆにこです。
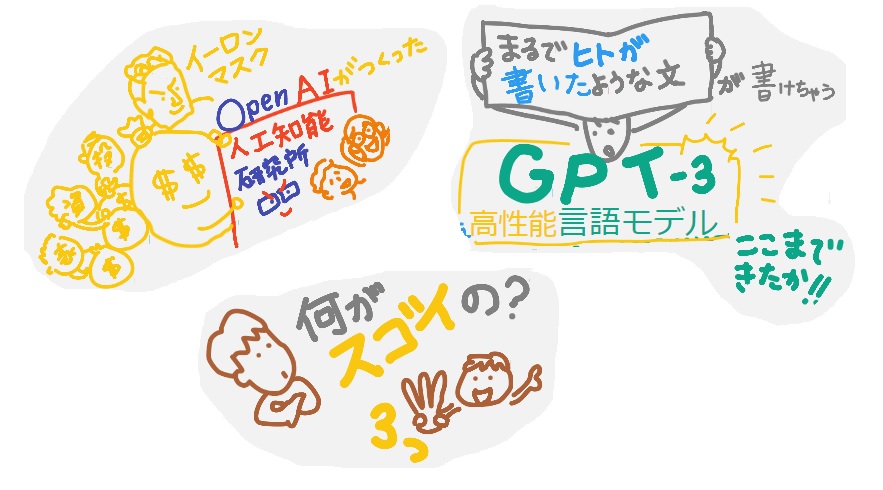
野村総研 未来創発センター「データサイエンスラボ」さまの新しい取り組み NRI「データサイエンス用語」の解説動画(絵巻物)第7弾がYouTubeアップされました。今回は(2分で解説)「高性能言語モデル GPT-3」です。
じーぴーてぃーすりぃ???
「GPT-3」をつくったのは、イーロン・マスクをはじめとする複数の投資家により設立された米国の人工知能(AI)研究所「OpenAI」、とのことなのですが、そもそも「GPT」って何? 何やら多くの人が「GPT-3」を使って遊んでいるらしいけど、なんでそんなに話題なの? 何がスゴイの?を解説したのが今回の動画です。欲張り過ぎてじつは2分をオーバーしてます。ちゃんと「スゴイ!」を伝えたい想いが、、、おさまりきらなかった。
https://www.youtube.com/channel/UCpy_3_wYutf5u0U4DdOziGQ
動画の前半では、そもそも「GPTって何?(自然言語生成って? 言語モデルって何?)」。後半では「GPT-3」の何がスゴイの? を解説しました。「音声あり&音声なし」の2バージョンで見てみると理解が深まります!
「GPT-3」詳しい用語解説はこちら。
https://www.nri.com/jp/knowledge/glossary/lst/alphabet/gpt_3
※GPT-3=Generative Pre-trained Transformer 3
「GPT-3」を一言で、シロウトのわたしが、説明するなら、、、
「これまでだれもが『そんな莫大なデータを学習させるには巨額なお金もかかるし、いくら時間があっても処理できないよ!』ってことを、桁違いのデータ(45TB!)からの学習を実現させちゃったことで、くだらないテーマから専門性の高い話題まで『あらゆる分野』で、まるで人間が書いていると疑わないほど自然な文章を作れるようになっちゃった!だ・け・じゃ・な・く、『言語で指示すれば』文章以外にも、例えばデザインしてくれたり楽譜を書いてくれたりと、いろんなアウトプットができるようになっちゃった、超・超・超・大規模で高性能なタスクをこなせちゃう『言語モデル』が、APIで公開されて誰でも遊べるようになっちゃったのがまたスゴイ!楽しい!クリエイティブ!」
です。長い。。。
そもそも1つ前のバージョン「GPT-2」が2019年に発表されたとき、そのすごさが話題になっていたそう。「ヒトが書いた新聞記事だと思って疑わなかった!」「(3億人のユーザーが使っている電子掲示板reddit上で)人間と会話していると思って、1週間気づかずやりとりをしていた!」などなど。
当時まだ、言葉の並び順がおかしかったりと、意味をなさない文章が出来ちゃったり「不自然な」文章が多かったのに、あまりに「こんなに『自然で』高度な文章が作成できるようになった!」ということは同時に「悪用されるかも!」ということで、発表自体を慎重に、リリースが段階的に行われたので、ますます話題になったそう。
そんな注目を浴びてきた「高性能な言語モデルGPTシリーズ」の最新バージョン「GPT-3」が、2020年7月にOpenAIから発表されて、さらにスゴイと話題に。しかも何やら、多くの人が「GPT-3」を使って遊んでいるらしい♪
【今回のNRIさんのこだわりもスゴイ】
ネットで「GPT-3」と検索するといろんな人が解説してますが、「2に比べて、3ではさらに何がスゴくなったのか」について言及されている記事はとっても少ない(あっても2と3がごっちゃになっている)。そこへ切り込んでいるのが、今回のNRIさんのこだわりのすばらしさでもあるので、そちらにも注目していただけたら嬉しいデス。
チャンネル登録もぜひ!
YouTube公式チャンネル NRIデータサイエンスラボ
https://www.youtube.com/channel/UCpy_3_wYutf5u0U4DdOziGQ
【ウラ話】
「じーぴーてぃーすりぃ???」
「GPT」という3つの英単語の並びが、どうにも覚えられず、、、「GDP?」「GT-R?」「GT3000?」いや違う「GTO?」「3PO?」「R2-D2?!」と頭の中には似て非なる英単語で大混乱。
ちなみに「GT-R」=日産の高級レーシングカー/「GT300」=カーレースSUPER GTの1つのクラス。GT=Grand Touring(Car)=レーシングカー/「GTO」=みなさんご存知?!ぐれーと・てぃーちゃー・おにづか!/「3PO」=正しくはCー3PO。「R2-D2」と共に愛すべきスター・ウォーズのキャラ。
そこで動画の中では2つの覚え方(語呂合わせ)こっそり書いてます。
最初は
「GPT」=GrateなPapa、とっても(T)すてき?
だったのが最後は、希望と想いを込めて
「GPT」=(人間にとって)GoodParTnerになるといいな~
になってます。探してみてネ。
【GPTのTは「Transformer」のT】
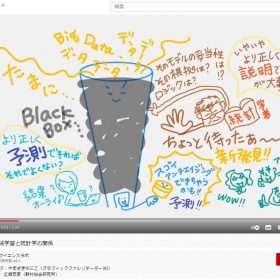
「Transformer」というアルゴリズムのおかげで、データを「並列処理(←これがスゴイ)できるようになった」=「高速で学習できるようになった」のだそう。これまでは時系列にニューラルネットワークの構造で処理していて時間かかっちゃっていたそう。ただこの並列処理はGPT-2には実現していたとのこと。動画で説明してる「GPT-3のスゴイ」は以下の3つです。


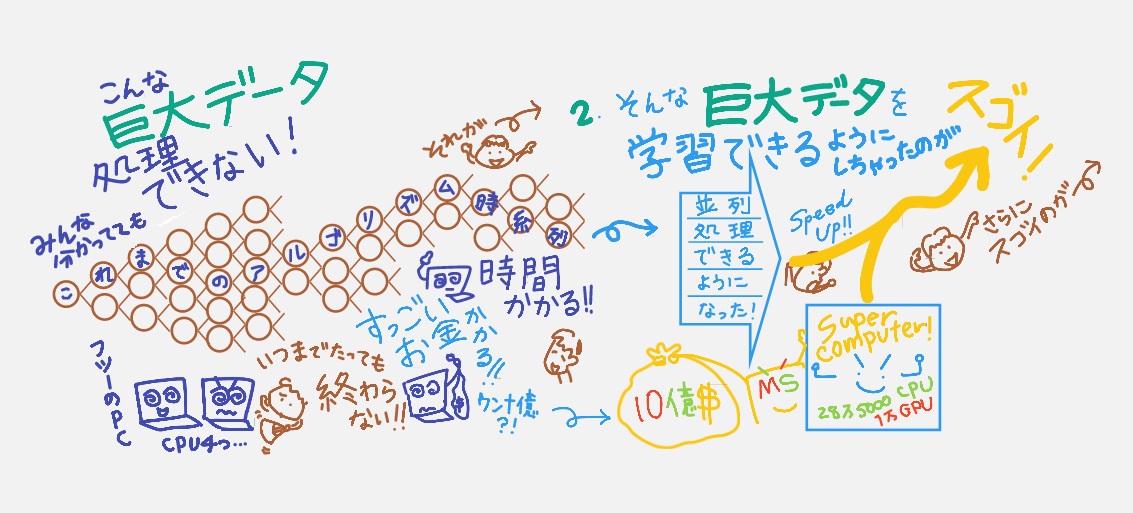
いや~シロウト的・素朴な疑問としては「大量データを学習させれば、そりゃ実現可能では?」とNRIの研究者のみなさんに尋ねたら「そんなカンタンじゃないんです!」という回答に驚いてました。とにかく本当に本当に本当に処理に時間ががかる=普通の性能のパソコンをいくら準備しても終わらない=電力使う=莫大なお金がかかる=一企業でそう簡単には実現できないレベル。それを今回、マイクロソフトのスーパーコンピューターを使えるようになって、やってのけちゃったそう。数十億円はかかっていてもおかしくないというウワサもあるらしい・「それってスゴくないですか?!」ということで、動画↑(スゴイの2つ目)に付け加えさせてもらってます。
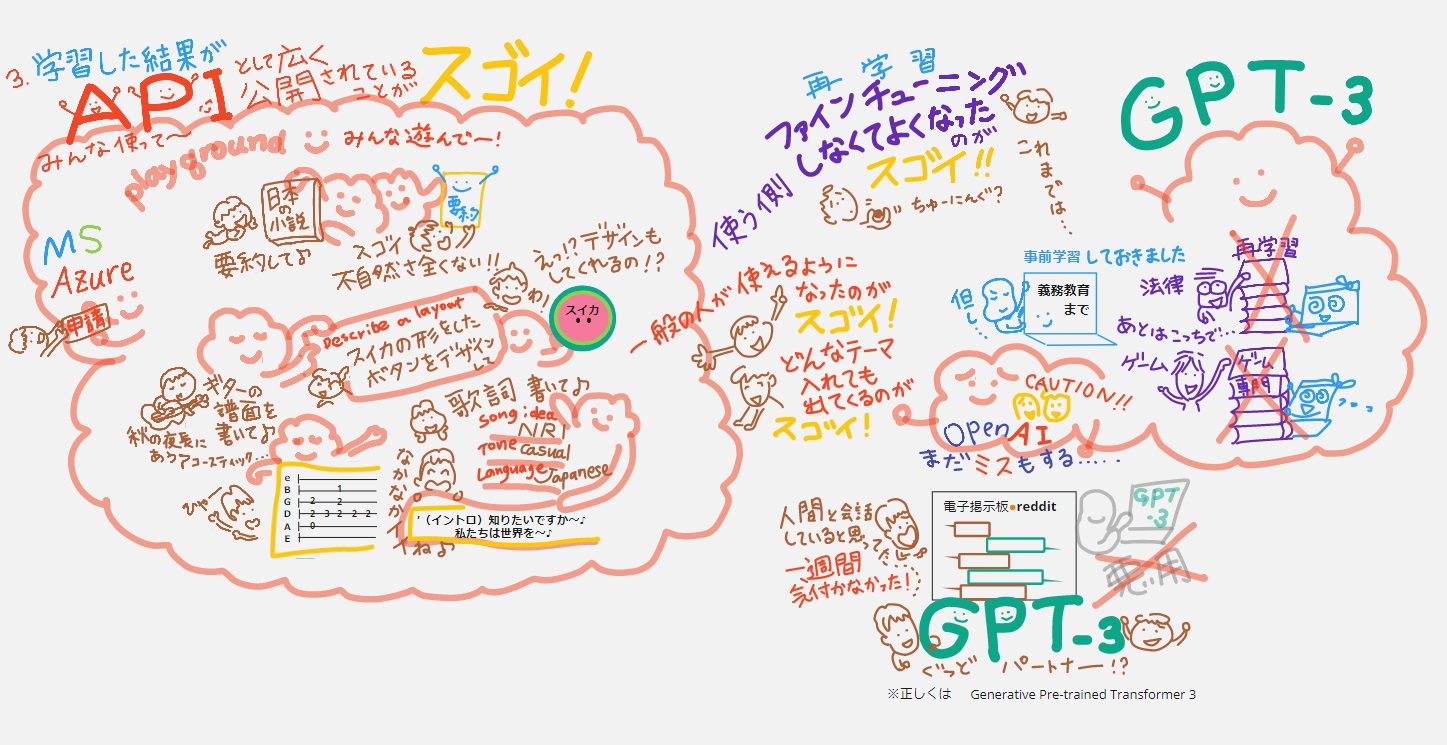
個人的にスゴイ!と驚いたのは(動画のさいご↑スゴイの3つ目に描いていますが)「GPT-3」ができることは単に「文章を人間が書いたように自然に書ける(要約したり、詩を書いたり…)」だけじゃない!ところ。
例えば、「スイカの形をしたボタンをデザインして」と言語を入れるとデザイン画像をつくってくれたり(デザインするプログラムは言語だから、アウトプットは言語だけじゃない!)、「秋の夜長にあったアコースティックギターの譜面を書いて」と言語を入れると楽譜をつくってくれたりと、高度なタスクを「言語」で入力するだけで、いろんなアウトプットを可能になってるんです。すごくないですか?!しかも、そうやって、いろんな人が遊べるようになったことが楽しくてスゴイ♪
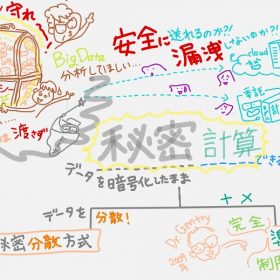
それを実現させたのが「学習した結果をマイクロソフトのAzure上で自然言語生成APIとして広く公開」したから。使う側が「ファインチューニング(再学習)しなくていい」から。ふぁいんちゅ~にんぐって?というのも動画に描いていますがこれまでは例えば「GRT-2をつかって法律に応用するなら、使う側が法律の専門用語を再学習させる必要があった」。それが不要となったわけです。
【基礎知識:言語モデルとは?】
「自然言語処理」>「自然言語生成」分野で、人間が書いり話したりすることば⇒学習して⇒単語の出現活率でモデル化したもの。
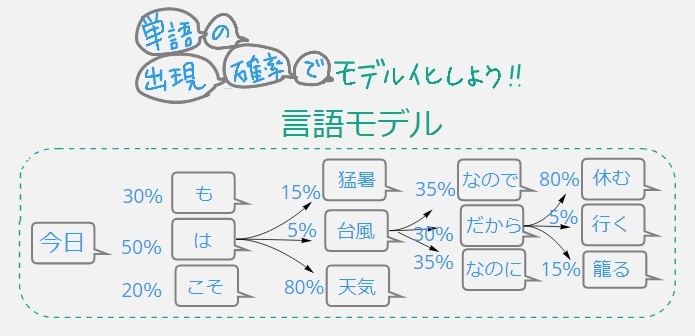
動画で紹介しているのはあくまでも例えですが、「今日」という単語が出てきたら「次にどんな単語が出現するかな?」を大規模データから学習することで、文章可能にになってきたそう。学習はまだまだ不十分だったのが、GPT-3で精度が固まり分野も一気に広がり、より人間がまるで書いた・話したように自然に言語を生成=「自然言語生成」。
これ一見、簡単に見えるんですが、英文なら単語と単語の間が空いているのでカンタンだけど、日本語は助詞でくっついているので区切りがそもそも分からないというので上の枝葉の図をつくるだけでも大変なんだそう。確かに~!