こんにちは。グラフィックファシリテーター®やまざきゆにこです。
野村総研 未来創発センター「データサイエンスラボ」さまの新しい取り組み NRI「データサイエンス用語」の解説動画(絵巻物)第5弾がYouTubeアップされました。今回は(2分で解説)「ベイズ統計」です。
ビル・ゲイツさんが「マイクロソフトの競争優位にたっているのはベイズ・テクノロジーのおかげ」と言ったことから、昔からあった「ベイズ統計」が一躍「ビジネスに活用できる」と注目されているそう。
(2分で解説)「ベイズ統計」NRIデータサイエンスラボ
https://www.youtube.com/watch?v=GVh7kUQYgRc
ベイズ統計のもとになっている「ベイズの定理」をビジネスに活用している事例としてよく紹介されるのが、迷惑メールフィルタリング、ということで動画もそれで解説することにしました。
【動画を見る前に、さて問題です】
メールの本文中に「無料」という表記があったら、あなたなら「それが迷惑メールかどうか」どう判断する?
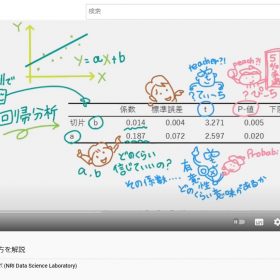
ちなみに「迷惑メールに識別されたメールの中で「無料」という表記が出現する割合:30%」「すべてのメールの中で「無料」という表記が出現する割合:10%」「全メールの中で、迷惑メールが占める割合は20%」と仮定する。わかりやすくするために、全体のメールの数を100通として計算してみてみると…?
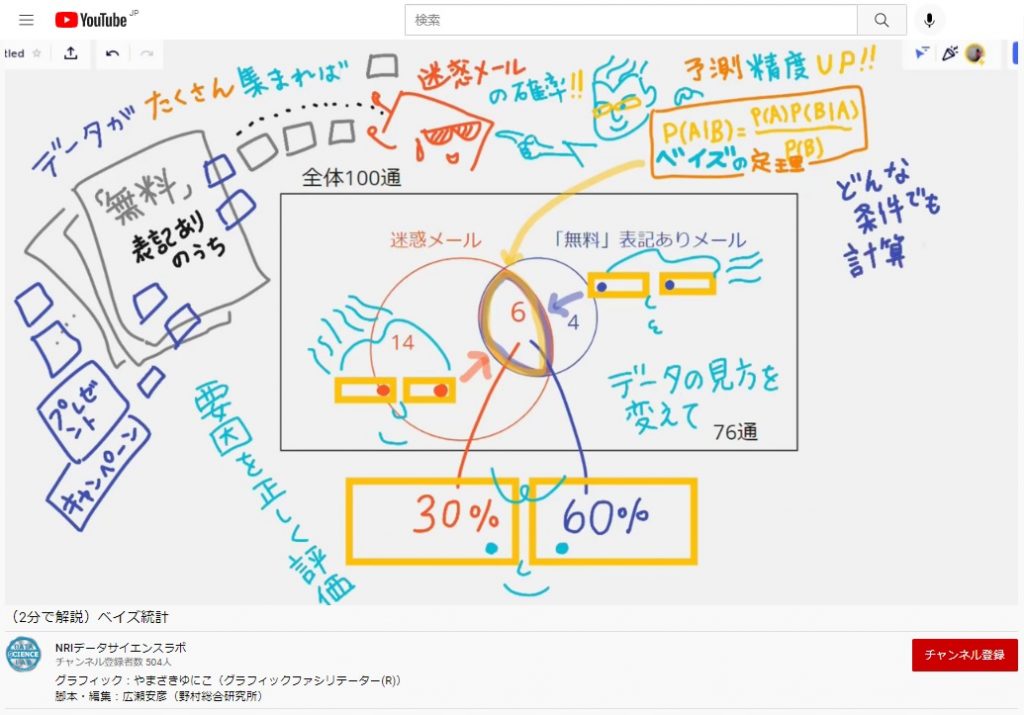
データシロウトのわたしなら安直に「迷惑メールフィルターに登録する単語に『無料』という言葉は入れないほうがいいんだろうな」なんて判断しちゃうところです。でも、『ベイズの定理』の考え方で確率を出してみると…
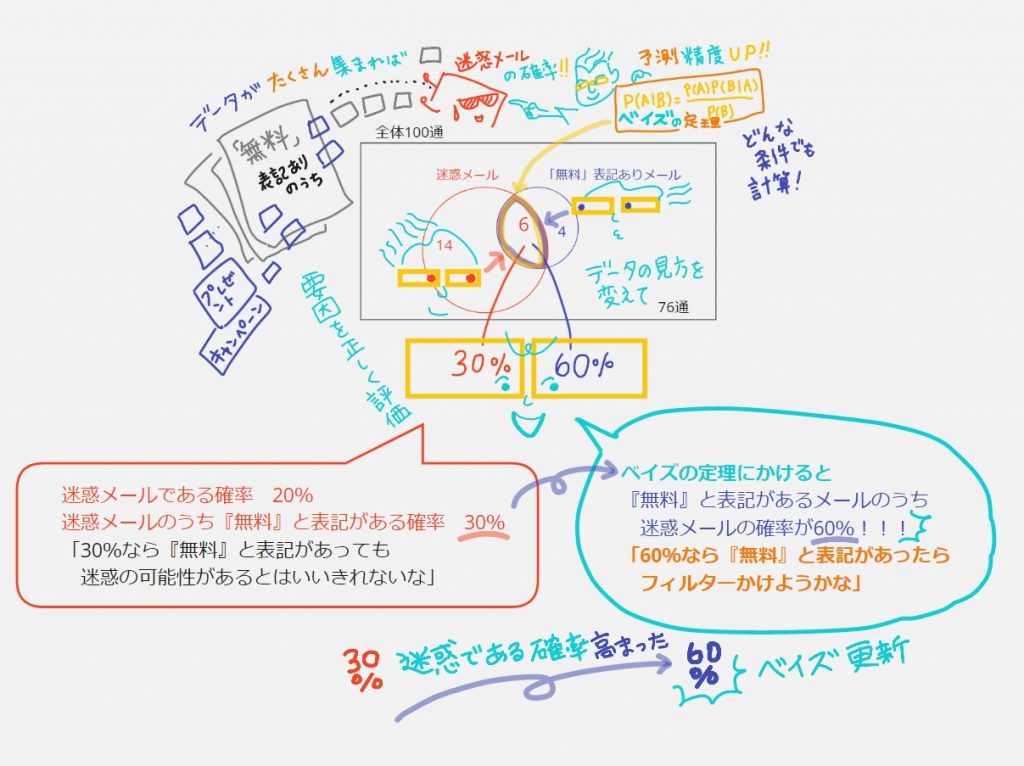
ベイズ統計の特長は2つ
①「データの見方を変えて」要因を正しく評価する:動画の中では「ベン図」を使って説明しています。「ベン図」で見ると分かりやすい。迷惑メール側から見ると「迷惑メールのうち無料表記がある割合は30%」でも、同じデータでも見方を変えて、無料表記あり側から見ると「無料表記があるメールのうち迷惑メールである割合は60%」となる!あれ?!迷惑である可能性(確率)が高まった!(30%→60%「ベイズ更新!」とも言うそう)
「迷惑メール」以外の例でよくあるのは「人間ドッグで陽性判定が出たからといって必ずしも病気じゃないよね」「無作為にPCR検査しても意味ないよね」みたいな話も、データを使って(こんなベン図で)説明されているわけです。
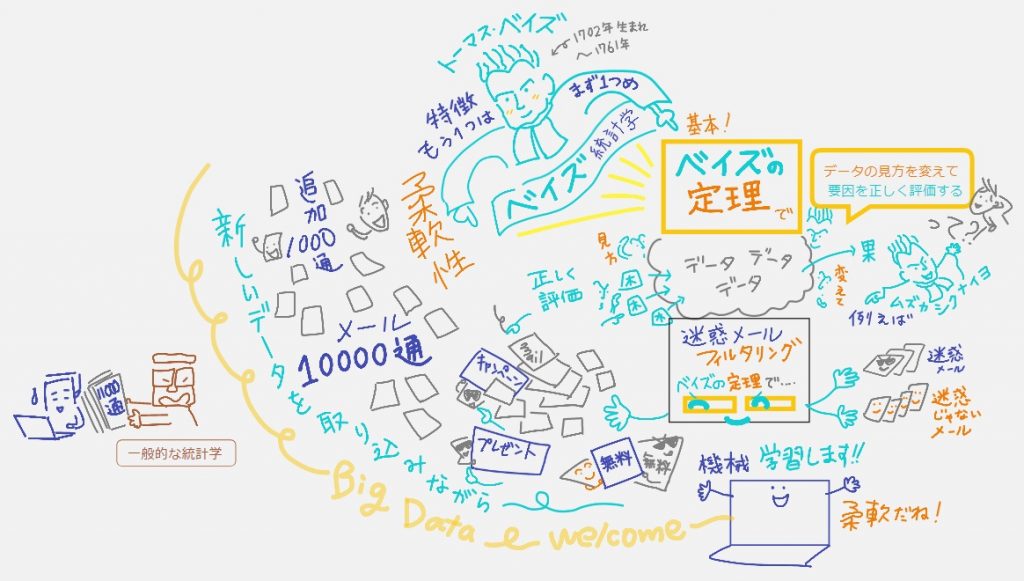
②新しいデータの取り込みに対する「柔軟性」:サンプルデータが少なくても比較的正しい確率を出せるよ、サンプルデータが増えれば自分で修正してさらに精度を挙げていく。…とのことなのですが統計シロウトのわたしとしては
「今の時代、サンプルデータが増えるたびに精度を上げていくのは、当たり前では?」と聞いたら「昔ながらの統計学では許されない。データが増えるたびにゼロから分析する必要がある」とのこと。
機械学習のおかげで再注目:昔からあったベイズ統計学が、今の時代の機械学習にハマって再注目され始めたのだそう。「ベイズさん、まさか今こんなに注目されてるとは思わないだろうなー」と思わず、ベイズさんがいつの時代に生きていた方なのかわざわざ調べてしまいました。(動画にわざわざ書いてます)ただ、サンプルデータがある程度集まってしまえば、これまでの統計学でも出来ちゃうことだから、②だけがフォーカスされやすいけど②はそんなにスゴイことではないのだそう。
ちなみに、「このメールは迷惑メールなのかどうか」を判断する材料も、現実問題は「無料」という単語だけでなく「キャンペーン」とか「プレゼント」とか「凍結」とか「振り込み」とか、、、どんどん複雑になるので、ベン図で理解するのは不可能。だからこそ機械学習の力を借りながらベイズの定理の公式が生きてくるってワケですね。
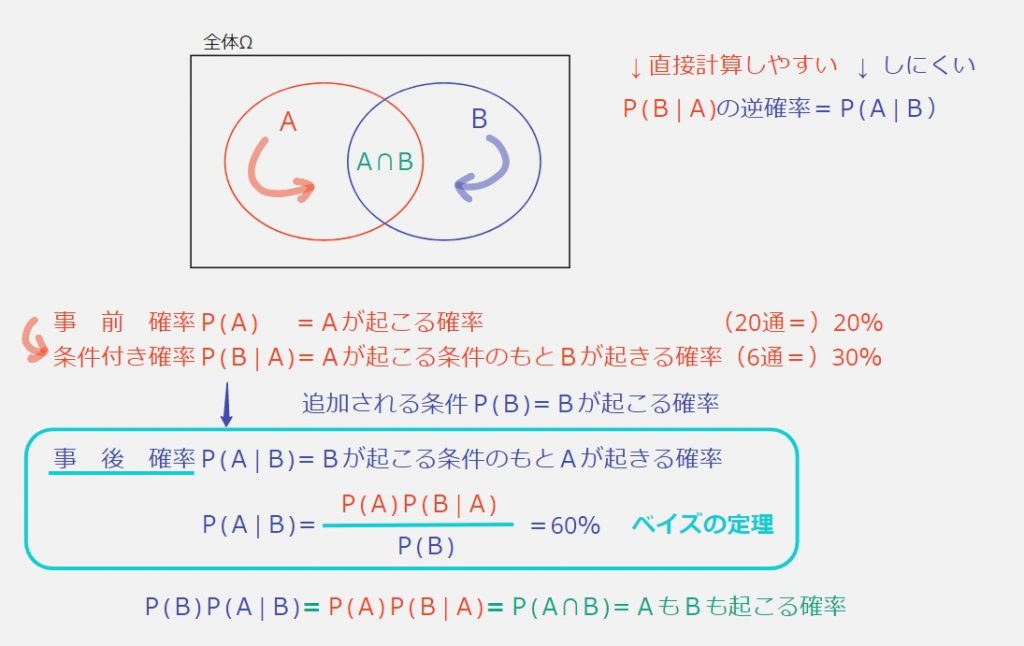
上の画像は動画の中では説明していなけれど、大事な用語なのでここに記載しておきます。(自分のために!)
事 前 確率P(A) =Aが起こる確率
条件付き確率P(B|A)=Aが起こる条件のもとBが起こる確率
↓条件B追加! P(B)=Bが起こる確率
事 後 確率P(A|B)=P(A)P(B|A)/P(B)=ベイズの定理
【ここだけの話】
「ベイズ統計学」は「因果推論」ほどホットではないそうですが、すでに「ベイズ」もネット上だけでもいろんな見方・意見が交わされていて、、、かなりの混乱状態?!ベイズ推計とかベイズ推論と呼んでいる人もいたり、②の部分だけをベイズの定理と言ったり、数式にわざわざしなくてもベン図で充分じゃないの、などなど、、、そこに一石を投じるのが今回のNRIさんの「ベイズ統計」解説になるのでは。
「ベイズ統計」用語解説ページはこちら。
https://www.nri.com/jp/knowledge/glossary/lst?syllable=ta
ぜひチャンネル登録してください。次回、第6弾は「コンテキストマッチング広告」です♪
YouTube公式チャンネル NRIデータサイエンスラボ
https://www.youtube.com/channel/UCpy_3_wYutf5u0U4DdOziGQ