こんにちは。グラフィックファシリテーター®やまざきゆにこです。
【NRIプレゼンツ☆知っておきたいデータサイエンス用語】
野村総研 未来創発センター「データサイエンスラボ」さまの新しい取り組み NRI「データサイエンス用語」の解説動画(絵巻物)第10弾がYouTubeアップされました。今回は(2分で解説)「自動発注」です。
動画では、スーパーがアイスクリームを「自動発注」する場合、
・「人間が発注する」のと何が違うの?
・「需要予測の精度が上がってきている」ってよく言われるけど、具体的に「機械学習」の何がどうスゴイの?
を解説しました。イントロのロカボのセリフはこんな感じ↓
子供 パパ今「自動発注」が盛り上がってるんだよ
パパ え?どうして?
子供 今まで難しかった商品の需要予測もできるようになってね
一般企業でも実装できるようになってね
パパ どうやって?何がどうスゴイの?ホント?精度上がってるってどこまで?
正直、NRIのデータサイエンティストさんから「自動発注」と聞いたときは、「へ?それがデータサイエンス用語???」だったのですが、なるほどみんなが「需要予測の精度がスゴイ」と興奮気味に苦しくも楽しそうに語る理由が分かりました。こりゃもはや人間の知能力量を超えてます。企業が扱いやすくなって、コスト削減にもフードロス削減にもつながるし、ビジネスで盛り上がらないわけがないです。
↓動画はこちら
「自動発注(Auto replenishment)」の詳しい用語解説はこちら。
https://www.nri.com/jp/knowledge/glossary/lst/sa/auto_replenishment
動画のポイントは以下↓静止画でぜひ押さえてください♪
わたしのNRIさんから受けたレクチャーメモを備忘録として記載しておきます。キーワードは
#需要予測 #特徴量 #画期的なモデル #勾配ブースティング決定木 #決定木 #ランダムフォレスト #安全在庫 #自動発注
まず抑えるキーワードは #特徴量
精度が上がったポイントは2つ。1つ目が「データを組み合わせて」 #特徴量 を増やして分析できるようになったから。「データが増えたから」精度が上がったのではなく、「データを組み合わせて」#特徴量を増やせるようになったのが、スゴイ。
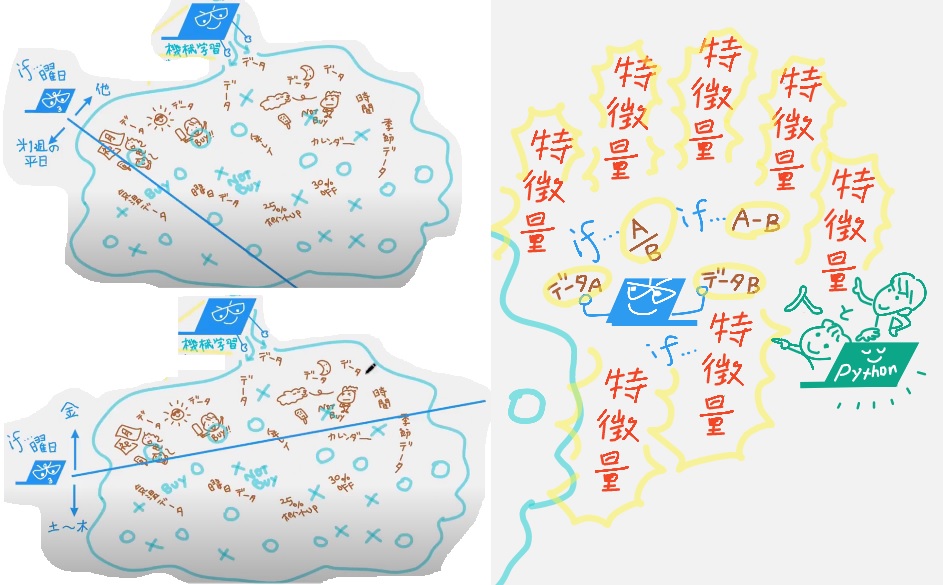
「データを組み合わせて」#特徴量を増やせるようになったとは、例えば
「気温」や「湿度」という元データは変わっていないけど、
「気温÷湿度」や「気温差」(前日の気温ー当日の気温)など、色んな特長をつくれて、
いろんな条件(#特徴量)、たとえば「気温差が5度以上の場合または5度未満の場合」とか「金曜日の場合またはそれ以外の曜日の場合」と、とにかくたくさんの #特徴量 を増やせるようになったおかげで、いろんな「if(もしも)」で計算できるようになって、どんどん精度が上がるようになっているそう。
ちなみに#特徴量をつくるのは人間だそう。例えば「湿度どこで切る? 20%? 30%? 40%?」「さすがに90%はありえないよね」と判断できるのは人間です。無駄な特徴量をつくっても無駄だよねということだそうです。機械任せじゃないんですねえ。パイソンのプログラムが書きやすくなっている、パイソンで特徴量をつくる整備が整ってきた。とのことで、上の右下にそんな絵もこっそり入れています。
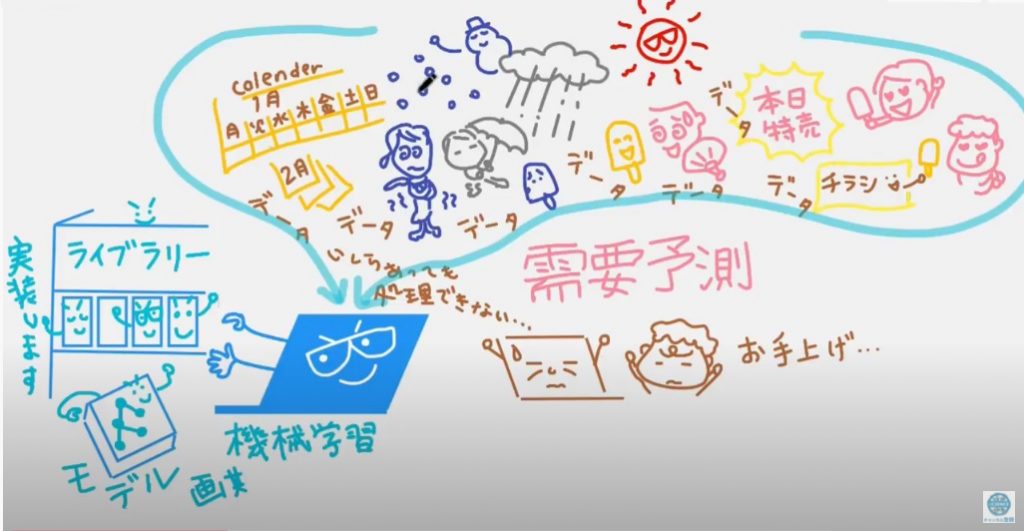
精度が上がったポイント2つのもう1つが、多くの企業がそれら無数の #特徴量 を使いこなして需要予測を決定できるようになったのが、機械学習でカンタンに実装できるライブラリーの登場のおかげ。#画期的なモデル(実装できるライブラリ)がいくつも登場しているそう。ライブラリとはすでにプログラミングされている便利なもの、ということで、絵の中では本棚に並べてみました。
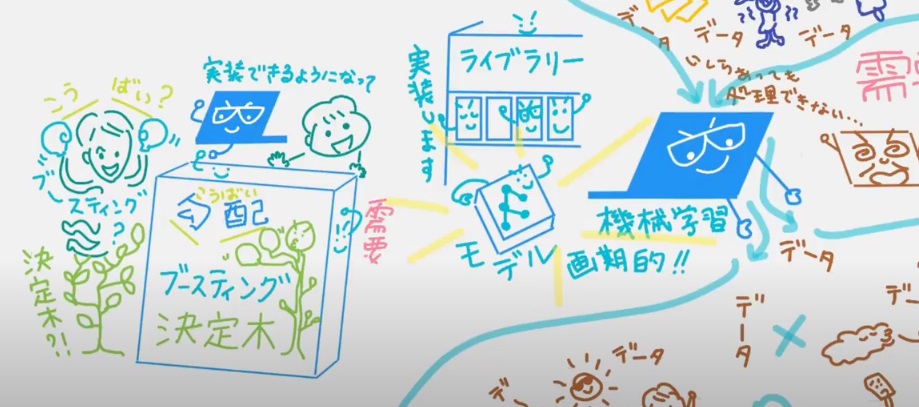
そんな画期的なモデルの1つ #勾配ブースティング決定木 。「勾配ブースティング決定木」という考え方は昔からあったそう。それが械学習の登場で、①無数の特徴量を扱えるようになって②それが実際に実装できるライブラリがそろって、正直、何も考えずにデータを入れれば需要予測が出来るようになっちゃったから、、、、盛り上がっているそうです。
動画ではデータを入れた機械の中で「どんな計算をしているの?」「需要予測の精度をどう高めているの?」というところを「勾配ブースティング決定木」で理解しておきましょうというストーリーになってます。#勾配ブースティング決定木 を理解するには↓この順番がおススメとのことで、動画の中でもこの順番で解説しています。
決定木→ランダムフォレスト→勾配ブースティング決定木
まず決定木↓まず一本の木からスタートです。
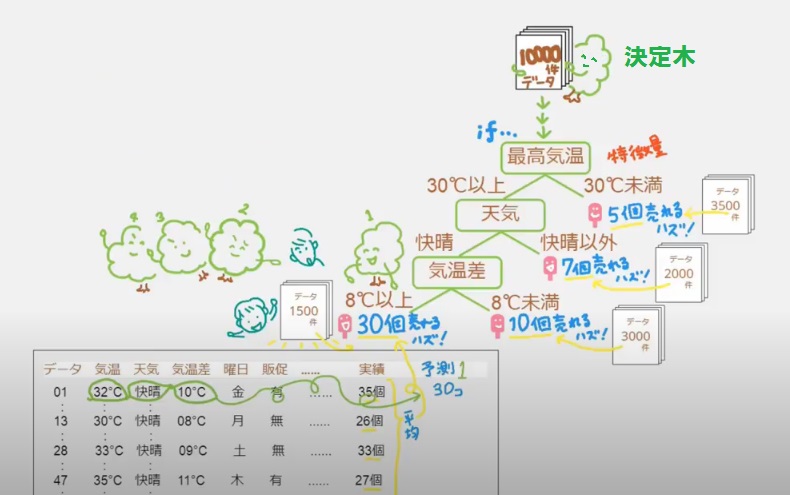
上から下に向かって枝は毎回2本に分かれて「if」をくりかえしています。「もし(if)最高気温が30℃以上/30℃未満なら」
決定木は一本しかないので、もっとたくさんあったら、さらに精度が高るよね!ということで、木たくさん集まって森になったのが↓ランダムフォレスト
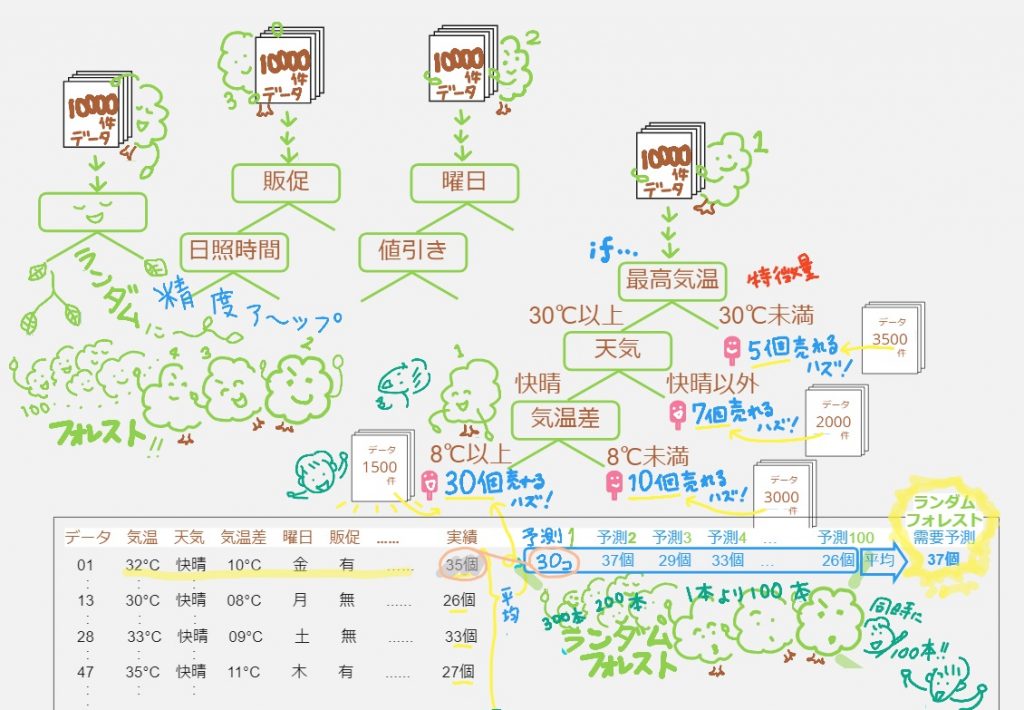
機械的にデータをランダムに当てはめて「一度に」たくさんの決定木をつくって平均をとって予測値を出します。ただ「一度に」たくさんの決定木をつくるのも荒っぽいよね、ということで、登場するのが勾配ブースティング決定木(LightGBM)↓たくさんの決定木があるのは同じだけど、ランダムフォレストとの違いは、一本目の決定木をつくったら「差分(誤差)」に注目。下の絵を見ていただくとイメージつかめますかね?
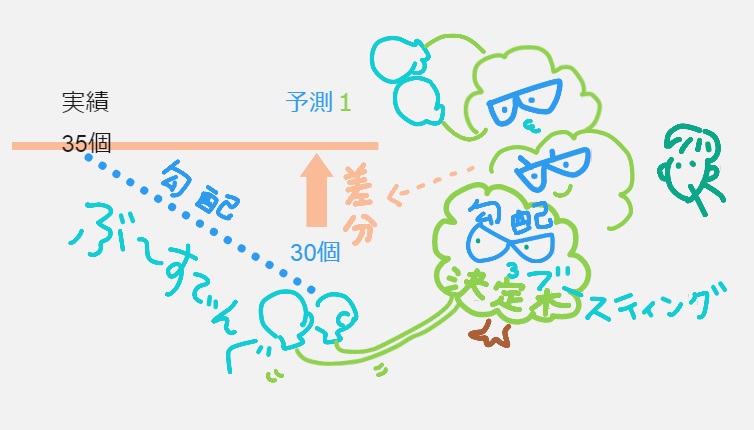
実績と決定木が出した予測数値の差分(誤差)を小さくしていくことに命をかけているのが勾配ブースティング決定木。「差分(誤差)」に注目して、二本目、三本目、、、、とつくっていきながら「差分(誤差)がいちばん小さくなるのはどんな特徴量のときか」を探していきます。
わたしのようなデータサイエンス初心者は、この勾配=差分(誤差)を「ぶ~すてぃんぐ」していく感じがつかめればよいのでは?と思って上の絵を描きました。こうして需要予測の精度を高めてるのね~と。
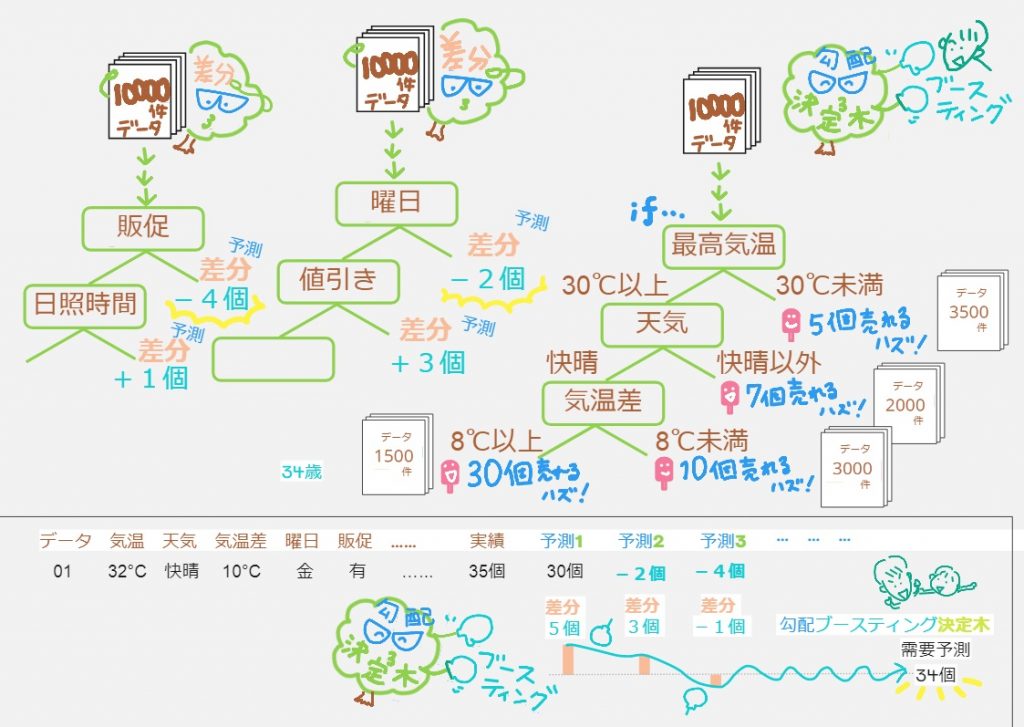
誤差がだんだん減っていくように100、、、1000、、、と決定木をつくっていって、しかも需要予測に影響がある特徴量を選んで決定してくれるそう。すごいですねー。
個人的にはデータサイエンティストさんが説明してくれたこの感覚的な表現が大好きなんですけど(^^)⇒「ランダムフォレストよりは枝葉の数は少ないが木の数は多い」「枝葉を細かくし過ぎない」「弱い木のまま他の木をつくっていく」
それではよく分からないと思うので、具体的な特徴量と数字を細かく入れて解説しています。
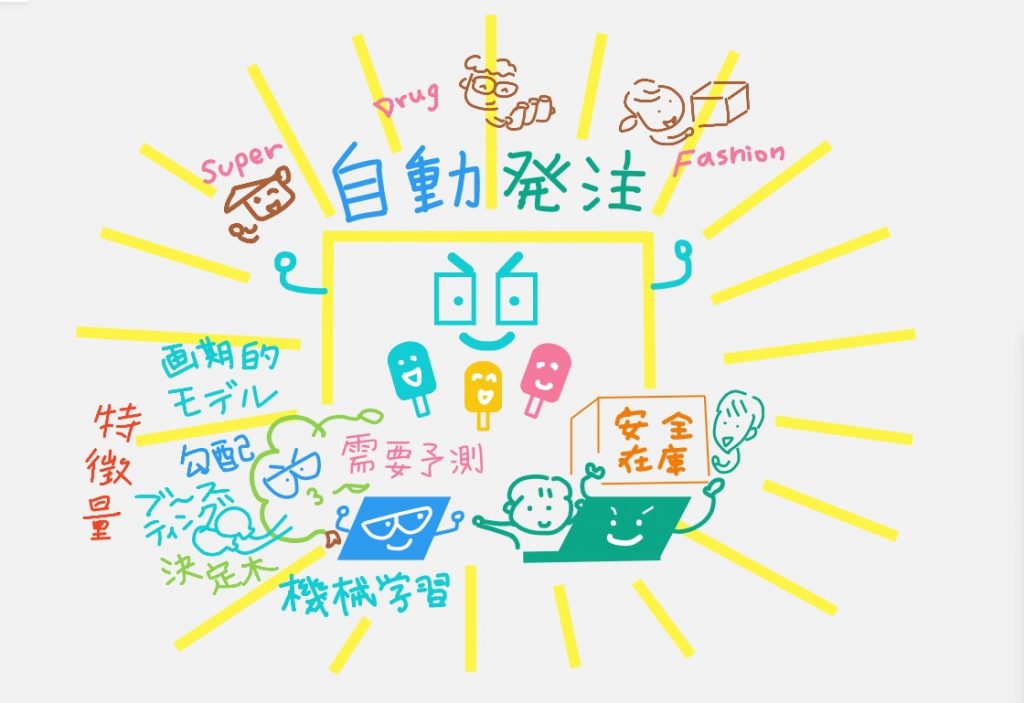
欠品が出たらそもそもアウト!#安全在庫 を考慮して係数かけないといけません。ということで、さいごの画像は「需要予測」だけじゃ足りないよ、「安全在庫」まで計算して初めて完成する「自動発注」の仕組みですよ、というのをお伝えしました。
ちなみに、面白そうなのは今後の進化。今はまだ扱えていない非構造化データ(たとえばセンサーで読み取ったカスタマー情報とか)まだまだいっぱいあるわけで、需要に影響を与えるであろうデータをさらに取り込めたら、ますます精度があがっていく、まだまだ無限の可能性が広がる世界です。
詳しくは用語解説「自動発注」をご覧ください。by NRI
https://www.nri.com/jp/knowledge/glossary/lst/sa/auto_replenishment
【動画制作ウラ話】
最初にNRIのデータサイエンティストさんにレクチャーを2時間ほど受けるのですが、1回で理解できることは稀で、、、、下の画像はわたしの手書きメモのほんの一部。絵を描くなんてさいごのさいご。動画を描く前にまずもって「理解」するまでにむっちゃくちゃ時間がかかっており、あたまの悪さに比例して、ウラ紙とボールペンの消費量は右肩上がりの創作現場です。
レクチャーを受けた後に、読み返してもう一回ちゃんと理解していこうとメモをしている過程で…「あれ?これってどゆこと?」「あれ?これってどゆこと?」となり…
とにかく難易度の高さの1つが、ネットで検索したところで、どこにも出てこない話を絵にしようとしているので、NRIの多忙なデータサイエンティストさんをまた質問攻めにすることになり、動画を完成させるまでにはだいぶご迷惑をかけています。
でも、世の中のデータサイエンティストさんたちですら「そこまで詳しく知らなくてもいいんじゃない?需要予測をはじき出してくれるんだし」と思われているかもしれないけれど「ほんとにそれでいいんですか?」「機械学習の中で何が起きているの?」にシロウト目線で挑んでいいというNRIさんの取り組み。がんばりたいです。

ちなみに今回の動画は私のこんなシロウト質問から完成してます。
「機械学習の中で何が起きているの?」
(↓もう少し具体的な質問にすると)
機械が計算している「ライブラリ」とやらにすでに組まれているプログラムは具体的にどんな計算をしているですか?
(↓もう少し具体的な質問にすると)
そもそもそのプログラムのもとになっている「画期的なモデル」とやらは、どんな考え方で、どんな計算をしているのですか?
答える側はウンザリだと思いますが、素朴なギモン、、、。とにかく毎回毎回、NRIの優しいデータサイエンティストのTさんに何度も何度も根気よ~く説明いただき、なんとか完成しております。
今後もぜひぜひチェックしてください。
チャンネル登録はこちら
YouTube公式チャンネル NRIデータサイエンスラボ
https://www.youtube.com/channel/UCpy_3_wYutf5u0U4DdOziGQ
他の動画もぜひ♪
第1弾「クッキーレス時代の到来とは?」
第2弾「機械学習と統計学の関係とは?」
第3弾「今注目の因果推論とは?」
第4弾「ディープラーニング」
第5弾「ベイズ統計」
第6弾「コンテクストマッチ広告」
第7弾「GPT-3」
第8弾「秘密計算」
第9弾「ベイジアンネットワーク」
第10弾「自動発注」